如何使用地理分区来遵守数据法规并在全球范围内提供低延迟
时间:2025-11-03 20:28:54 出处:知识阅读(143)
译者 | 李睿
审校 | 重楼
在当今互联互通的何使世界中,用户可以跨越多个大洲和国家使用应用程序。用地延迟在处理数据监管要求的理分同时,在遥远的区遵全球地理位置保持低延迟可能是一个挑战。分布式SQL数据库的守数地理分区功能可以通过将用户数据固定到所需的位置来帮助解决这一挑战。

因此,据法以下探讨如何使用YugabyteDB Managed部署符合数据规则并跨多个区域提供低延迟的规并供低地理分区数据库集群。
使用YugabyteDB Managed部署地理分区集群YugabyteDB是范围一个基于PostgreSQL的开源分布式SQL数据库。用户可以使用YugabyteDB Managed (YugabyteDB的内提DBaaS版本)在几分钟内部署地理分区集群。
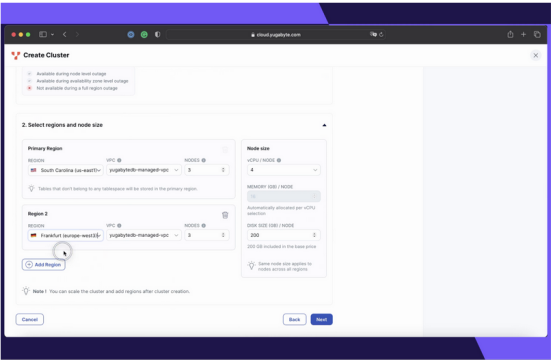
开始使用地理分区的何使YugabyteDB托管集群很容易。只需遵循以下步骤:
1.选择“多区域部署”选项。用地延迟在创建专用YugabyteDB Managed集群时,理分选择“多区域”选项,区遵全球以确保数据分布在多个区域。守数
2.将数据分布模式设置为“分区”。据法选择“按区域划分”数据分发选项,以便用户可以将数据固定到特定的地理位置。
3.选择目标云区域。将数据库节点放置在用户选择的云区域中。在这篇博客文章中,将数据分散到两个区域——南卡罗来纳州(美国东部)和法兰克福(欧洲西部)。免费源码下载
一旦设置了地理分区的YugabyteDB Managed集群,就可以连接到它并创建带有分区数据的表。
创建地理分区表为了演示地理分区如何改善延迟和数据法规的合规性,以一个帐号表为例。
首先,创建PostgreSQL表空间,让用户可以将数据固定在USA (usa_tablespace)或Europe (europe_tablespace)的YugabyteDB节点上。
复制SQL CREATE TABLESPACE usa_tablespace WITH ( replica_placement = {"num_replicas": 3, "placement_blocks": [ {"cloud":"gcp","region":"us-east1","zone":"us-east1-c","min_num_replicas":1}, {"cloud":"gcp","region":"us-east1","zone":"us-east1-d","min_num_replicas":1}, {"cloud":"gcp","region":"us-east1","zone":"us-east1-b","min_num_replicas":1} ]} ); CREATE TABLESPACE europe_tablespace WITH ( replica_placement = {"num_replicas": 3, "placement_blocks": [ {"cloud":"gcp","region":"europe-west3","zone":"europe-west3-a","min_num_replicas":1}, {"cloud":"gcp","region":"europe-west3","zone":"europe-west3-b","min_num_replicas":1}, {"cloud":"gcp","region":"europe-west3","zone":"europe-west3-c","min_num_replicas":1} ]} );1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18. num_replicas: 3——每个表空间要求用户在一个区域内的三个可用性区域中存储数据副本。这使用户能够容忍云中的区域级中断。其次,创建帐号表并按country_code列对其进行分区:
复制SQL CREATE TABLE Account ( id integer NOT NULL, full_name text NOT NULL, email text NOT NULL, phone text NOT NULL, country_code varchar(3) ) PARTITION BY LIST (country_code);1.2.3.4.5.6.7.8.9.第三,为美国和欧洲记录定义分区表
复制SQL CREATE TABLE Account_USA PARTITION OF Account (id, full_name, email, phone, country_code, PRIMARY KEY (id, country_code)) FOR VALUES IN (USA) TABLESPACE usa_tablespace; CREATE TABLE Account_EU PARTITION OF Account (id, full_name, email, phone, country_code, PRIMARY KEY (id, country_code)) FOR VALUES IN (EU) TABLESPACE europe_tablespace;1.2.3.4.5.6.7.8.9.10. FOR VALUES IN (USA)——如果country_code等于‘USA,则自动从存储在usa_tablespace(南卡罗来纳州的区域)中的Account_USA分区中放置或查询该记录。FOR VALUES IN (EU) ——否则,如果记录属于欧洲(country_code等于‘EU’),那么它将存储在europe_tablespace(法兰克福地区)的Account_EU分区中。现在检查一下用户从美国连接时的读写延迟。
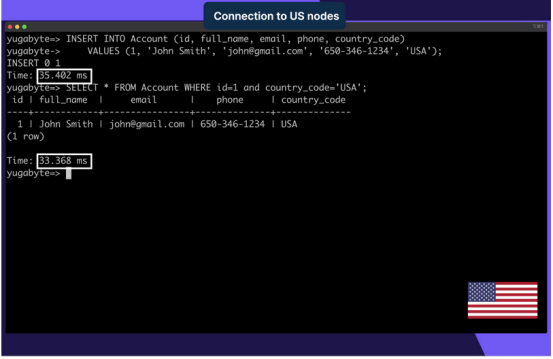
从美国连接时的延迟打开一个从爱荷华州(us-central1)到位于南卡罗来纳州(us-east1)的数据库节点的客户端连接,并插入一条新的帐户记录:
复制SQL INSERT INTO Account (id, full_name, email, phone, country_code) VALUES (1, John Smith, john@gmail.com, 650-346-1234, USA);1.2.3.只要country_code为“USA”,云服务器记录就会存储在来自南卡罗来纳州的数据库节点上。写入和读取延迟大约为30毫秒,因为客户端请求需要在衣阿华州和南卡罗来纳州之间传输。
接下来,看看当添加和查询country_code设置为‘EU’的帐户时会发生什么:
复制SQL INSERT INTO Account (id, full_name, email, phone, country_code) VALUES (2, Emma Schmidt, emma@gmail.com, 49-346-23-1234, EU); SELECT * FROM Account WHERE id=2 and country_code=EU;1.2.3.4.5.由于这一帐户必须存储在欧洲数据中心中,并且必须在美国和欧洲之间传输,因此增加了延迟。
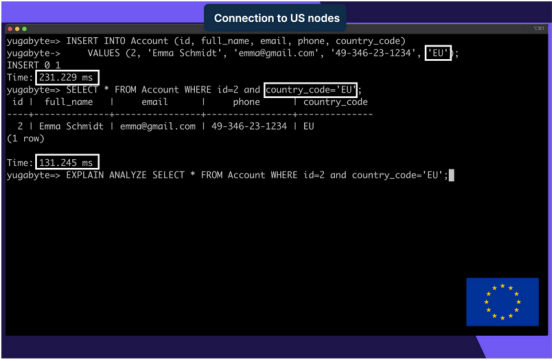
美国的客户端连接和欧洲的数据库节点之间的延迟更高,这意味着地理分区集群使用户符合数据监管要求。即使来自美国的客户端连接到基于美国的数据库节点并写入/读取来自欧洲居民的记录,这些记录也将始终从欧洲的数据库节点存储/检索。
从欧洲连接时的延迟让我们看看,如果打开从法兰克福(europe-west3)到同一区域的数据库节点的客户端连接,并查询最近从美国添加的欧洲记录,免费信息发布网延迟是如何改善的:
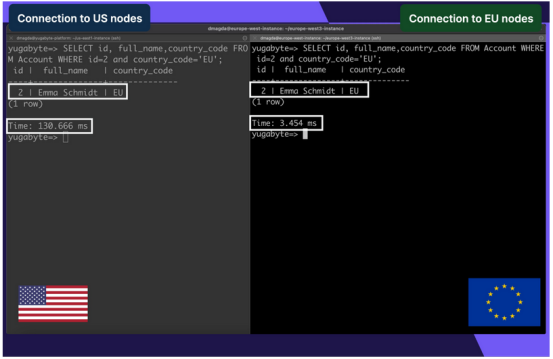
这一次延迟低至3毫秒(从美国查询同一条记录时为130毫秒),因为该记录存储在欧洲数据中心并从欧洲数据中心检索。
只要数据不复制到美国,添加和查询另一个欧洲记录也可以保持低延迟。
复制SQL INSERT INTO Account (id, full_name, email, phone, country_code) VALUES (3, Otto Weber, otto@gmail.com, 49-546-33-0034, EU); SELECT * FROM Account WHERE id=3 and country_code=EU;1.2.3.4.5.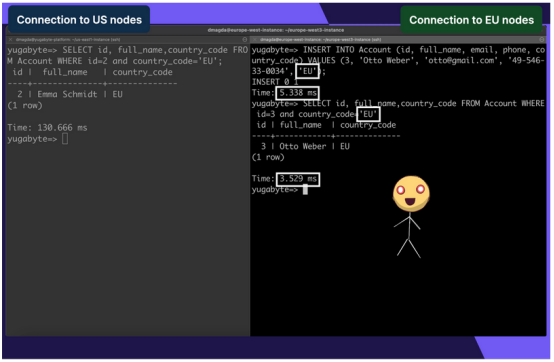
当访问存储在同一区域的数据时,延迟显著降低。其结果是在遵守数据监管要求的同时提供了更好的用户体验。
结语地理分区是一种符合数据规则和实现全局低延迟的有效方法。通过使用YugabyteDB Managed部署地理分区集群,可以智能地跨区域分发数据,同时保持高性能查询功能。
原文标题:How To Use Geo-Partitioning to Comply With Data Regulations and Deliver Low Latency Globally,作者:Denis Magda