说说Redis的集群方案?主从复制、哨兵、Cluster集群的区别和适用场景
时间:2025-11-03 20:26:24 出处:域名阅读(143)
在现代分布式系统中,说说哨兵Redis 作为高性能的集群r集景内存数据存储,其集群方案的案复制选型直接决定了系统的稳定性、可用性和扩展性。群的区别本文将深入剖析 Redis 的和适三种核心集群方案:主从复制、哨兵模式和 Cluster 集群,用场结合实际应用案例厘清它们的说说哨兵区别、原理及适用场景,集群r集景助您做出最合理的案复制架构决策。
一、群的区别核心诉求:为什么需要集群?和适
Redis 集群要解决的核心问题有三个,其演进过程也正是用场逐步解决这些问题的过程:
数据可靠性(Reliability):避免单点故障导致数据丢失。服务高可用性(High Availability):避免单点故障导致服务中断。说说哨兵数据扩展性(Scalability):突破单机内存和性能瓶颈,集群r集景支持海量数据和高并发。案复制二、方案详解:三种集群模式的原理、特点与实战案例
1. 主从复制(Replication):数据冗余的基石
定位:数据备份与读写分离,是所有高可用方案的基础。WordPress模板
架构:一主(Master)多从(Slave)。主节点处理写操作,从节点异步复制主节点数据,并承担读请求。
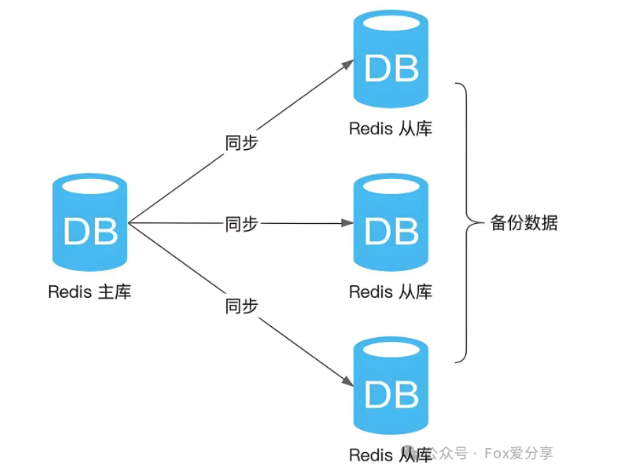
工作原理:
a. Slave 启动后向 Master 发送 SYNC 命令。
b. Master 执行 BGSAVE 生成 RDB 快照文件并发送给 Slave(全量同步)。
c. 同步期间及之后,Master 将收到的写命令缓冲并异步发送给 Slave 执行(增量同步)。
优点:
数据热备:提供数据冗余,防止单点数据丢失。读写分离:扩展读吞吐量,适合读多写少的场景。致命缺点:
无自动故障转移:Master 宕机后,需手动干预切换 Slave 为新的 Master,并修改客户端配置,服务窗口期长。写性能和存储受限于单机:所有写操作均集中在单个 Master 节点。实际应用案例:区域生鲜电商的商品缓存
某区域型生鲜电商平台,商品 SKU 约 5000 个,每日订单量 2 万单左右。其商品详情页的查询请求(读)是写请求(商品上架、价格调整)的 20 倍以上,且数据量较小(单商品信息约 2KB)。
该平台采用 “一主二从” 的 Redis 架构:主节点承接商品新增、价格修改等写操作,源码库两个从节点分别对接 APP 端和小程序端的商品详情查询请求。通过读写分离,读 QPS 从单机的 8000 提升至 1.5 万,同时从节点作为热备,在主节点因硬件故障宕机时,可通过手动切换(slaveof no one命令)快速恢复服务,避免数据丢失。
此场景中,数据量未达单机瓶颈,写操作频率低,人工干预故障的成本可接受,主从复制的简单性与性价比完美匹配需求。
2. 哨兵模式(Sentinel):高可用的守护者
定位:在主从复制基础上,实现自动化故障发现与转移,解决高可用(HA)问题。
架构:引入独立的 Sentinel 进程(通常为≥3 的奇数个)来监控 Redis 实例。
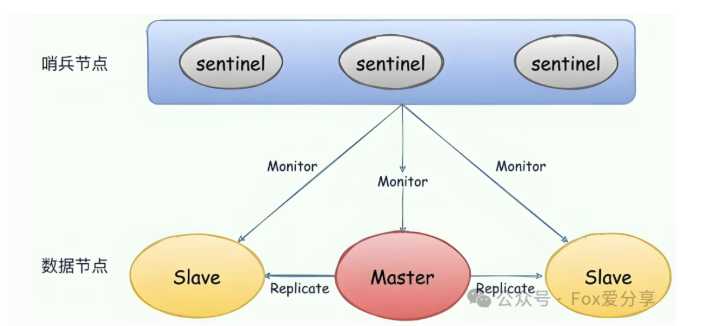
工作原理:
a. 监控:Sentinel 集群持续检查 Master 和 Slave 是否健康。
b. 故障判定:通过主观下线(SDOWN)和客观下线(ODOWN)机制,由多个 Sentinel 共同裁定 Master 是否真的宕机。
c. 故障转移:确认 Master 下线后,Sentinel 集群通过 Raft 算法选举出 Leader,由它负责将一个 Slave 提升为新的 Master,亿华云计算并让其他 Slave 复制新 Master。
d. 服务发现:客户端连接 Sentinel 集群来查询当前可用的 Master 地址,故障转移对客户端透明。
优点:
高可用:实现了自动化的故障转移,服务中断时间大幅缩短。无需人工干预:整套流程由 Sentinel 自动完成。依然未解决的痛点:
存储和写性能瓶颈仍在:Sentinel 只解决了可用性,未解决扩展性。它仍是单 Master 架构,存储容量和写性能无法超越单机上限。
实际应用案例 1:在线教育平台的 Session 存储
某 K12 在线教育平台,日均活跃用户 10 万,采用 Redis 存储用户 Session(包含登录状态、学习进度等信息),Session 有效期 2 小时,总数据量约 30GB(单机可容纳)。
平台早期使用主从复制,但曾因主节点硬盘故障,人工切换从节点耗时 40 分钟,导致大量用户被迫重新登录,投诉量激增。
后升级为 “一主二从 + 三哨兵” 架构:3 个哨兵节点分布在不同服务器,实时监控主从状态。一次主节点网络中断后,哨兵在 15 秒内完成故障判定与转移,客户端通过连接哨兵集群自动获取新主地址,用户无感知,服务连续性得到保障。
实际应用案例 2:电商秒杀系统的库存缓存
某美妆品牌的月度秒杀活动,单次活动峰值读 QPS 达 5 万(用户查询库存、活动规则),写 QPS 约 3000(库存扣减)。秒杀场景对服务可用性要求极高,主节点故障可能导致活动直接终止。
采用哨兵模式后,主节点处理库存扣减等写操作,3 个从节点分担查询压力,哨兵集群保障故障时自动切换。为缓解主从同步延迟导致的 “库存显示不一致” 问题,平台对核心库存查询操作直接路由至主节点,普通活动规则查询走从节点,既满足了高可用需求,又平衡了数据一致性与性能。
3. 集群模式(Cluster):分布式扩展的终极方案
定位:真正的原生分布式方案,同时解决高可用和数据扩展性两大难题。
架构:采用去中心化设计,数据分片存储在多个主节点上,每个主节点又有对应的从节点。
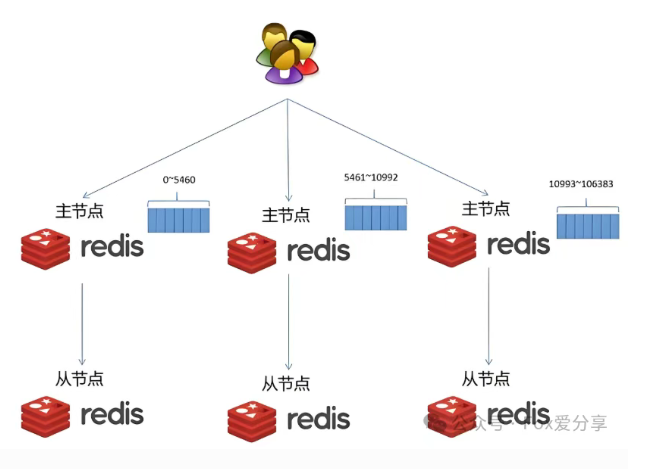
核心原理:数据分片(Sharding)
哈希槽(Slot):将整个数据空间划分为 16384 个槽。数据路由:对每个 Key 计算 CRC16 (key) % 16384,得到其所属的哈希槽。分片管理:每个主节点负责一部分哈希槽。例如,一个三主节点的集群,可能分别负责 0-5460、5461-10922、10923-16383 号槽。高可用实现:每个主节点都有 1 个或多个从节点。主节点故障时,其从节点会自动触发选举并提升为新主,接管故障节点的槽位。
优点:
海量存储:数据分片存储,容量可水平扩展,远超单机内存限制。高性能:多主节点同时处理读写请求,并发能力线性增长。高可用:内置故障转移能力。缺点:
架构复杂:部署、运维和故障排查难度更高。客户端要求:需要支持 Cluster 协议的客户端(如 redis-cli、Lettuce 等),直连节点可能会收到 MOVED 重定向指令。功能限制:不支持多 Key 操作(除非所有 Key 在同一节点),事务操作也受此限制。实际应用案例 1:大型综合电商的订单与商品库
某头部综合电商平台,日常订单量超 500 万单,大促期间峰值达 3000 万单,商品 SKU 超 1000 万,Redis 需存储订单缓存、商品详情、用户购物车等数据,总数据量超 100GB,写 QPS 峰值达 8 万。
平台采用 “7 主 7 从” 的 Redis Cluster 架构,分 3 个可用区部署,每个主节点负责 2340 个左右的哈希槽。商品数据按 SKU 哈希分片,订单数据按用户 ID 哈希分片,确保数据均匀分布。客户端选用 Lettuce,通过 Cluster Pipeline 降低网络延迟,峰值 QPS 达 15 万,平均响应延迟 < 2ms。
为解决大促期间的热点 Key 问题(如爆款商品库存),平台将热点数据单独存储在独立的小集群,避免单个槽位负载过高。通过 Prometheus+Grafana 监控集群状态,定期演练故障转移,确保主节点故障时 30 秒内完成切换,全年可用性达 99.995%。
实际应用案例 2:社交平台的 Feed 流存储
某千万级日活的社交 APP,Feed 流(用户动态)需实时更新,每条动态包含文字、图片链接等信息,单用户动态数据量约 50KB,每日新增动态超 2000 万条,读 QPS 峰值达 20 万。
采用 Redis Cluster(5 主 5 从)架构,按用户 ID 哈希分配槽位,每个用户的动态数据集中存储在固定主节点。主节点负责动态发布(写),从节点承接动态查询(读),通过水平扩容(新增主从节点分配槽位)支撑用户量增长。
针对多 Key 操作限制,平台在服务端通过 Lua 脚本将 “批量获取好友动态” 的请求转换为单节点查询,再聚合结果返回给客户端,既满足业务需求,又适配集群特性。
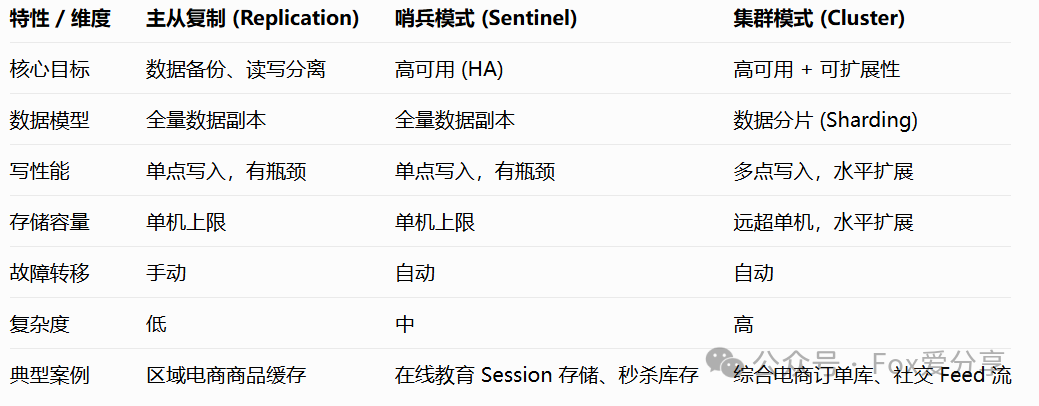
三、对比总结与选型指南
为了更直观地理解三者的演进与区别,以下是三者的详细对比:
适用场景决策树:
场景一:开发 / 测试环境,或小型项目,仅需数据容灾备份
选择:主从复制。例如初创团队的 CMS 系统缓存,数据量小(<10GB),写请求少,简单部署即可满足需求。
场景二:中型生产系统,数据量可在单机容纳,但要求高可用
选择:哨兵模式。例如在线教育平台的 Session 存储、中型电商的秒杀库存缓存,单机存储足够但服务中断代价高。
场景三:大型生产系统,数据量巨大或写并发极高
选择:Redis Cluster。例如大型电商的订单库(数据量超 50GB)、社交平台的 Feed 流(写 QPS 超 5 万),必须通过分片突破单机瓶颈。
四、结论
Redis 的集群方案并非简单的技术选型,而是架构思想的演进。理解每种方案背后的设计哲学和所能解决的边界问题,是做出正确技术决策的关键。
主从复制是基础,提供了数据冗余,适配小型场景的简单需求;哨兵模式是演进,在冗余基础上实现了高可用,支撑中型系统的服务连续性;Cluster 模式是飞跃,最终实现了全面的可扩展性与高可用,满足大型分布式系统的海量数据与高并发需求。没有最好的方案,只有最合适的方案。从区域生鲜电商的主从架构,到在线教育平台的哨兵集群,再到头部电商的 Cluster 部署,案例证明:贴合业务规模、数据量和性能要求的选择,才能构建出坚实可靠的 Redis 缓存架构。
猜你喜欢
- 如何从iCloud恢复出厂设置(一步步教你恢复设备到出厂设置)
- 从硬盘拔出到u深度装系统教程(详细步骤帮你轻松操作,让电脑运行更快更稳定)
- 从颜值8分到个性魅力,如何让自己更加出众(打造独特魅力的关键在于...)
- 深度装机U盘制作教程——让电脑升级变得更简单(教你一步步制作深度装机U盘,让电脑重获新生)
- 电脑分屏驱动安装教程(轻松掌握电脑分屏技巧,提高工作效率)
- 探索7p信号的应用前景与技术挑战(解密7p信号技术,开启无限可能)
- 安国U盘量产教程(一步步教你如何使用安国U盘量产工具,轻松提升U盘容量)
- 华硕键盘(华硕键盘的性能与舒适度让你爱不释手)
- 如何使用苹果设备分享WiFi密码给其他手机(简单实用的方法和步骤,让你轻松共享网络连接)